朝鮮中央放送や平壌放送の時報音をPythonで再現しました。
ダウンロードページからmp3形式でダウンロードできます。
本ページでは再現した時報音の解説とPythonコードを掲載します。
解説
朝鮮中央放送や平壌放送では、正時の3秒前から1秒ごとに約0.21秒の550Hzの正弦波パルスが流れます(予報音)。 正時から約3秒間は1100Hzの正弦波トーンが流れます(正報音)。
フェードアウト
正報音の振幅は時間と共に減衰していきます。
そこで、今回はシグモイド関数を用いてフェードアウトを再現しました。 シグモイド関数を用いたフェードアウトの振幅 は、時刻 に対して次式で表されます。
上式で は変化のスピードを決定するパラメータで、大きいほど急激に、小さいほど緩やかに変化します。 は振幅が半分となる時刻です。
今回はハンドチューニングでフェードアウトのパラメータを としました( は正時の時刻)。
フェードイン
実際の時報音を確認すると正報音がフェードインで鳴り始めていたので、フェードアウトと同様シグモイド関数で再現しました。
シグモイド関数を用いたフェードインの振幅 は次式で表されます。 パラメータの意味は と同様です。
フェードインのパラメータは としました。
Pythonによる時報音の再現
時報音をwav形式で出力するPythonスクリプト timesingnal.py を(AIと一緒に)作成しました。
変数 sample_rate, silence_duration, limit_amplitude はそれぞれサンプリングレート、冒頭の無音部分の長さ、最大振幅を設定しています。
Source (timesignal.py)
# Time Signal Generator
# Output: output.wav
# Last updated on 2026/01/16
import numpy as np
import wave
import matplotlib.pyplot as plt
# --- Parameters ---
# Sampling rate [Hz]
sample_rate = 8000
# Duration of silence [s]
silence_duration = 2 - 0.072
# - 0.072s: offset inserted by libmp3lame (8kbps)
# Amplitude limit (1: 0dB, 0.5: -3dB)
limit_amplitude = 1
# --- 1. Time signal generation ---
sound_duration = 6
sound_samples = int(sample_rate * sound_duration)
t_sound = np.linspace(0, sound_duration, sound_samples, endpoint=False)
waveform_sound = np.zeros(sound_samples)
# [ 550Hz Tone ]
time550Hz = [(0, 0.21), (1, 1.21), (2, 2.21)]
# Amplitude of 550Hz sine wave
amp550Hz = 1
for start, end in time550Hz:
start_idx = int(start * sample_rate)
end_idx = int(end * sample_rate)
waveform_sound[start_idx:end_idx] = amp550Hz * np.sin(2 * np.pi * 550 * t_sound[start_idx:end_idx])
# [ 1100Hz Tone ]
start_idx = int(3.0 * sample_rate)
end_idx = int(6.0 * sample_rate)
waveform_sound[start_idx:end_idx] = np.sin(2 * np.pi * 1100 * t_sound[start_idx:end_idx])
# Amplitude of 1100Hz sine wave
# (1) Fade out
fade_start = 3.0
fade_center = 4.55
k = 6 # Parameter of sigmoid function
amp1100Hz = np.ones_like(t_sound)
fade_mask = (t_sound >= fade_start)
amp1100Hz[fade_mask] = 1 / (1 + np.exp(k * (t_sound[fade_mask] - fade_center)))
# (2) Fade in
fade_start = 3.0
fade_center = 3.02
k = 500 # Parameter of sigmoid function
fade_mask = (t_sound >= fade_start)
amp1100Hz[fade_mask] *= 1 / (1 + np.exp(k * -(t_sound[fade_mask] - fade_center)))
waveform_sound *= amp1100Hz
# Limit amplitude
waveform_sound *= limit_amplitude
# --- 2. Scilence at the beginning ---
silence_samples = int(sample_rate * silence_duration)
waveform_silence = np.zeros(silence_samples)
# Concatenate silence and time signal
waveform_total = np.concatenate([waveform_silence, waveform_sound])
total_samples = silence_samples + sound_samples
# --- 3. Save as a WAV file ---
# Scale for 16bit signed PCM
scalePCM = 32767
final_waveform = (waveform_total * scalePCM).astype(np.int16)
with wave.open('output.wav', 'w') as wav_file:
wav_file.setparams((1, 2, sample_rate, total_samples, 'NONE', 'not compressed'))
wav_file.writeframes(final_waveform.tobytes())
# --- Plot output waveform ---
t_total = np.linspace(0, silence_duration + sound_duration, total_samples, endpoint=False)
plt.figure(figsize=(12, 4))
plt.plot(t_total - (silence_duration + 3), final_waveform / scalePCM)
plt.xlabel('Time [s]')
plt.ylabel('Amplitude')
plt.xlim((-3.5, 3.5))
plt.grid(True)
plt.tight_layout()
plt.show()timesignal.py を実行すると output.wav に出力された音声信号の波形が以下のようにプロットされます。
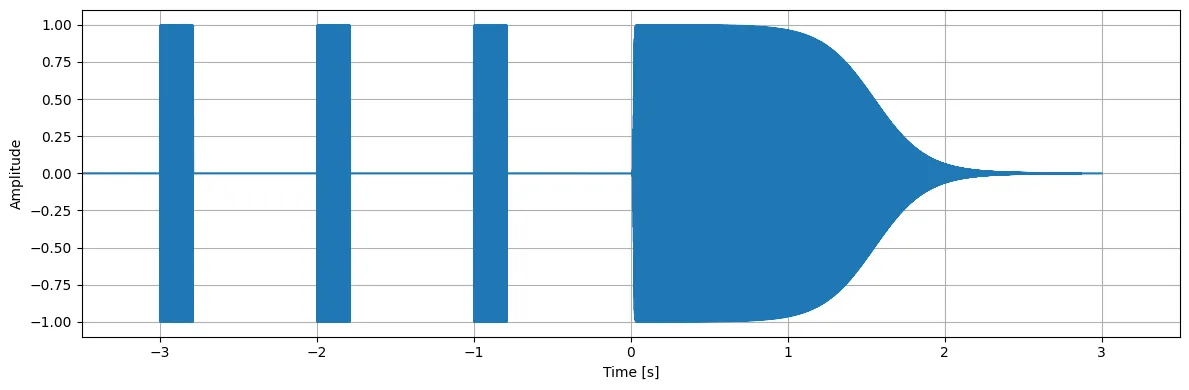
横軸0秒付近を見ると、正時を知らせる音がいきなり始まるのではなく、フェードインしていることが分かります。
ダウンロードページで配布している timesignal.mp3 は output.wav をmp3形式に変換したものです。
以下のコマンドで作成しています。
python3 timesignal.py; ffmpeg -i output.wav -ab 8k timesignal.mp3mp3への変換時に72ミリ秒ほど遅延が発生したので、上のコードでは無音部分の長さ silence_duration を設定する際にあらかじめ差し引いています。
予報音までの無音が2秒間、予報音が3秒、正報音が3秒なので、合計8秒間の音声として出力されています。
おわりに
今回はPythonで時報音を再現してみました。
フェードアウトやフェードインが結構曲線的でしたが、シグモイド関数である程度近づけることができました。
なお再現にあたっては、intchosonのサイトで配信された朝鮮中央放送の衛星ラジオの音声1とDRM受信された朝鮮中央放送のオープニング音声2を参考にしました。
脚注
-
Source: KCBS 2026-01-01 00:59-01:00 via https://intchoson.com/kcbs. 2026年の年越し放送の録音から(YouTube) ↩
-
Drm Test(KCBS Pyongyang) Startup - YouTube、dtv-jp。2021年9月15日5時の朝鮮中央放送オープニングがDRM波で非常に良好に復調されています。 ↩